在Deepseek刷屏全球AI界,并让华尔街对其进行紧张评估时,它又一次给全世界带来了惊喜。
北京时间2025年1月28日凌晨,DeepSeek团队发布两款多模态框架——Janus-Pro 和 JanusFlow。
这一次,我们想重点聊聊Janus-Pro。
Janus-Pro是一款统一多模态理解与生成的创新框架,是 Janus 的升级版本,它通过解耦视觉编码的方式,极大提升了模型在不同任务中的适配性与性能。
它在图像生成基准测试中表现卓越,超越了 OpenAI 的 “文生图” 模型 DALL-E 3。此外,和之前的Janus系列一致,它同样选择开源。
其一共包含两个参数模型,分别是 15 亿参数的 JanusPro 1.5B 和 70 亿参数的 JanusPro 7B。
让我们先来看看Janus-Pro发布后,硅谷的反应如何:
RundownAI负责人在X上发布的新模型推文的讨论足有230万阅读,再次引爆AI圈。
各路大神也纷纷转载,知名行研机构“科比西信函(The Kobeissi Letter)”发布的内容转载阅读超百万,AI大V“Chubby”也第一时间罗列了该模型的技术细节。
这些讨论中,最核心的关注点是对模型的测试表现和能力的惊叹:Janus-Pro 7B直接在理解和生成两方面都超越了LLaVA、Dalle 3和SD XL这样的主流选手。
在阅读DeepSeek发布的相关技术报告时,我们发现一个关键点:它的思路与杨立昆和谢赛宁领衔的MetaMorph项目有异曲同工之妙。
只是,DeepSeek在这条路上尝试得更彻底。

两个在开源模型领域“执牛耳”的模型公司,打算携手改变多模态大一统模型的范式。这一次,真的和杨立昆所说,是开源模型的胜利了。
AI的双眼革命:通过“分工”达到统一的尝试多模态大一统模型的理念最早由谷歌提出,Gemini 便是这一理念的代表之作。其核心设计在于运用 Transformer 架构,将文本、图像、音频等多种模态的数据进行统一处理,实现对不同模态信息的理解与生成。
这一创新架构突破了传统模型在处理单一模态数据时的局限性,开启了多模态融合发展的新方向。
这样,同一个模型就既可以“读懂图片”,又可以“生成图片”。
这和当时Stable Diffusion、Dalle这类主流文生图模型完全不同,这些模型都需要另一套模型去理解文本,它们只管生成。这需要维护多个完整模型,占用更多存储空间和计算资源,而且模型之间无法共享学习到的知识。
而像GPT-4V(OpenAI 开发的多模态大模型,也属于多模态大一统模型的范畴)等,则只能理解图像、转译为文字,但无法生成。
既然大一统多模态模型这么好,能既理解图像,又生成图像,为什么到今天OpenAI还在用GPT4V+Dalle这样的流水线模型处理理解和生成呢?
因为大一统多模态模型既难训练,效果又不好。
比如Deepseek最初也采用了统一的Transformer架构来处理文生图任务。理论上,这种方法很优雅:同一个模型,采用一个多模态的编码器,既理解文本输入,又负责生成图像。
但实践中,他们发现这种设计存在严重的性能瓶颈。
比如来自智谱的CogVLM,它就用了单一的ViT 解码器,试图将输入图像经过patch化处理后,打包成一个统一的视觉任务编码器,让它去处理视觉理解和视觉生成,之后通过特征融合来协调不同任务。
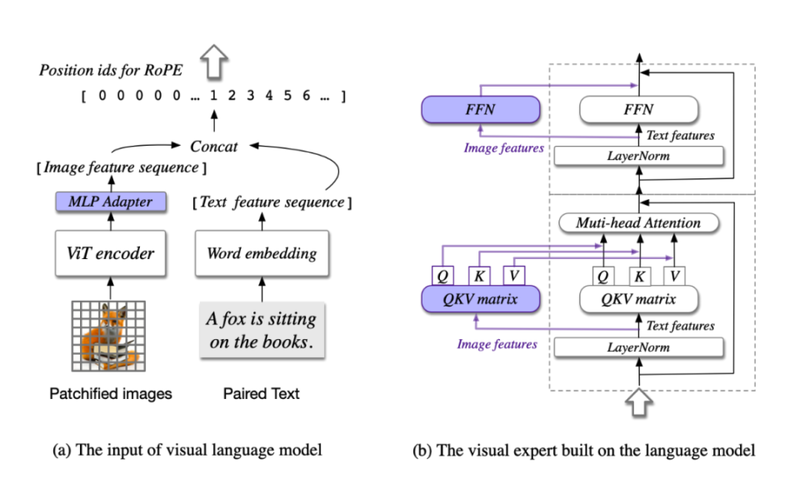
然而,因为这种单解码器的复杂度,在高分辨率图像生成时,统一模型的计算复杂度呈指数级增长,需要海量多模态数据,且训练过程难以收敛。
更糟的是,模型在优化文本理解时往往会损害图像生成能力,反之亦然。这种能力干扰(capacity interference)成为了统一架构的致命伤。
简单来说,就是让一个解码器又以美术评论家的身份写评论,又要它化身画家创作新作品,结果就是,两者它都做得很一般。
Meta的研究者在MetaMorph项目中也不约而同地进行了一次转化:他们都放弃了"编码器大一统"的设计理念,转而采用“专门化”的方案。
虽然没有单一编码器优雅,但依然可以在同一个Transformer架构中完成,还是“大一统”里的“小分工”。
简单来讲,他们给模型配置了两个不同的编码器,这就像两只眼睛一样。
在DeepSeek的Janus Pro中,第一只"眼睛"(SigLIP编码器)专门负责理解图像,它能提取图像的高层语义特征,并关注图像的整体含义和场景关系。它就像一个经验丰富的艺术评论家,能够快速抓住画作的要点。
第二只"眼睛"(VQ tokenizer编码器)则专门用于创作,将图像转换为离散的 token 序列,像画家一样关注细节的处理。
这两个"眼睛"虽然各司其职,但它们共享同一个"大脑"(Transformer),虽然两个眼睛独立的在工作,但在这个大脑中,DeepSeek 给Transformer加上了图像理解的注意力头,让它们的知识能够融合。
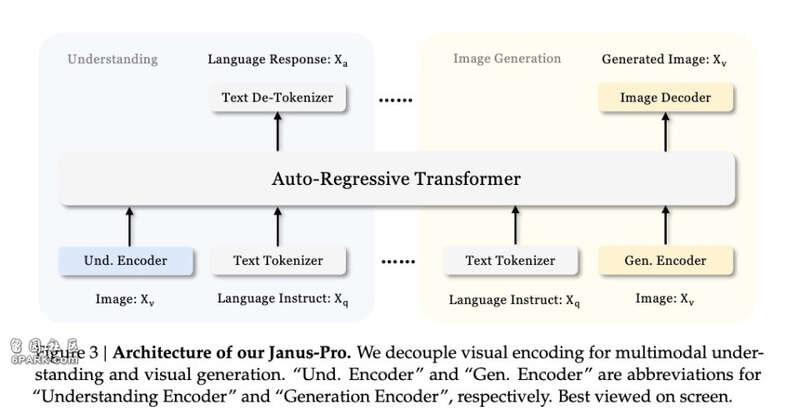
与DeepSeek从头开始训练不同,Meta是直接在已有的语言模型上,加上视觉注意力头和视觉编码,经过约20万张图文对的微调训练,成功“唤醒”了大语言模型自有的图像理解能力。
靠着双头编码器,因为有足够的视觉理解,输出的是文本和视觉两种token。因此再加上一个扩散模型就可以生成图像了。
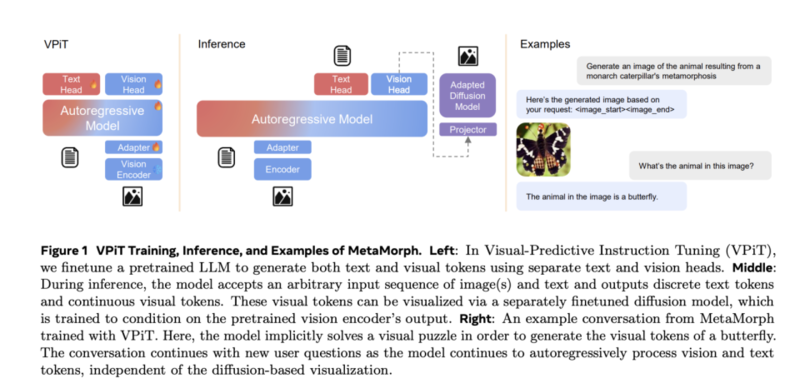
而DeepSeek则更进一步,在图像方面就用了生成和理解两个解码器。让这个多头框架,实现了图像生成和理解的大一统。
不再执着于统一的编码模式。这听起来似乎很简单,但这个想法却颠覆了过去的传统。
过去的大一统模型是受人脑启发,认为通用智能应该有统一的信息处理机制。他们期望通过统一架构发现模态间的深层联系希望实现真正的跨模态理解,而不是表面的特征映射。然而他们低估了Transformer本身的能力,就算有不同的信息处理器,Transformer依然可以在其内容达成容和理解。
DeepSeek对此的命名也很有趣:Janus-Pro中Janus是一名古罗马双面神,拥有两个头。寓意满满。
颠覆传统的多段训练:DeepSeek的能效奇迹发生之处对于DeepSeek来讲,架构的更新从来不是唯一的创新。他们能实现相对较低的成本去训练模型,很大程度上也是对于训练的严格掌控。
在Janus-Pro的训练上,DeepSeek采用了三段式的方法,每一段都有大胆的尝试。
第一阶段:锁参数也能提升性能
传统认知中,多模态AI训练的第一阶段只被视为预热。在这个阶段,模型通过预训练视觉编码器来学习基础的视觉特征提取能力,仅占用总训练时间的15%左右。
但DeepSeek研究团队的最新发现颠覆了这一认知。他们发现一个反直觉的现象:即使将大语言模型(LLM)的参数完全锁定,仅通过训练适配器,模型就能够掌握复杂的像素依赖关系。这种方法不仅大幅降低了训练成本和复杂度,还带来了显著的性能提升。
基于这一发现,研究团队将第一阶段的训练时间延长到总时长的25-30%。结果表明,模型的基础视觉理解能力得到了质的飞跃。
第二阶段:弃用ImageNet,拥抱真实
在多模态AI训练中,第二阶段“模态对齐阶段”一直被视为核心环节。传统方法在这个阶段会同时训练视觉和语言模型,致力于实现两种模态之间的对齐。这个过程通常会消耗超过50%的训练时间,占用大量计算资源。
长期以来,ImageNet数据集在视觉模型训练中扮演着"安全毯"的角色 - 几乎所有视觉模型都要在其上进行训练。在传统训练流程中,高达67%的训练步数都用在了ImageNet上。
但DeepSeek团队做出了一个颠覆性的决定:完全放弃在第二阶段使用ImageNet。这个决定基于一个关键观察:ImageNet的数据分布与实际应用场景存在显著差异,导致大量训练实际上是无效的,造成了严重的资源浪费。
取而代之的是直接使用真实的文生图数据进行训练。这个改变带来了显著成效:训练时间减少40%、生成质量提升35%、模型对真实场景的适应性大幅提升。
这就像是让孩子直接在真实环境中学习,而不是局限于模拟环境。这种方法不仅更高效,也更符合实际应用需求。
第三阶段:东方的神秘配比,达到最高效果
在多模态模型训练中,第三阶段的任务特定微调一直被视为"点睛之笔"。这个阶段通过使用任务相关的数据集来微调模型参数,对模型的最终表现起着关键作用。
近期,DeepSeek团队在这一阶段取得了突破性进展。传统方法中,多模态数据、纯文本数据和文生图数据的配比通常是7:3:10。而通过大量实验,DeepSeek发现了更优的配比方案:将这三类数据调整为5:1:4的比例。
在文生图数据部分,团队创新性地引入了合成美学数据,与真实数据形成1:1的配比。之所以增加文生图合成数据的占比,是因为用了这种方法后,模型不仅收敛更快,生成结果也更加稳定。最重要的是输出图像的美学质量得到显著提升。
在这三个阶段中,DeepSeek都用开创性的训练方法极限提效。因此Janus-Pro-7B 模型仅仅用了32个节点、256张A100、14天的时间就完成了训练。
大一统的真正实力:全能还最强极低的训练成本,7B的小身材,换来的却是能力的绝杀,而且是理解、生成双杀。
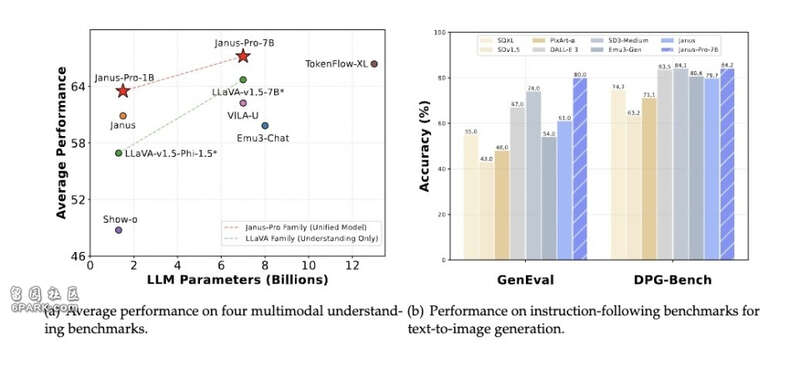
从基准测试来看,Janus-Pro-7B的表现令人印象深刻。在多模态理解基准MMBench上,它获得了79.2分的成绩,超越了此前的最佳水平,包括Janus(69.4分)、TokenFlow(68.9分)和MetaMorph(75.2分)。
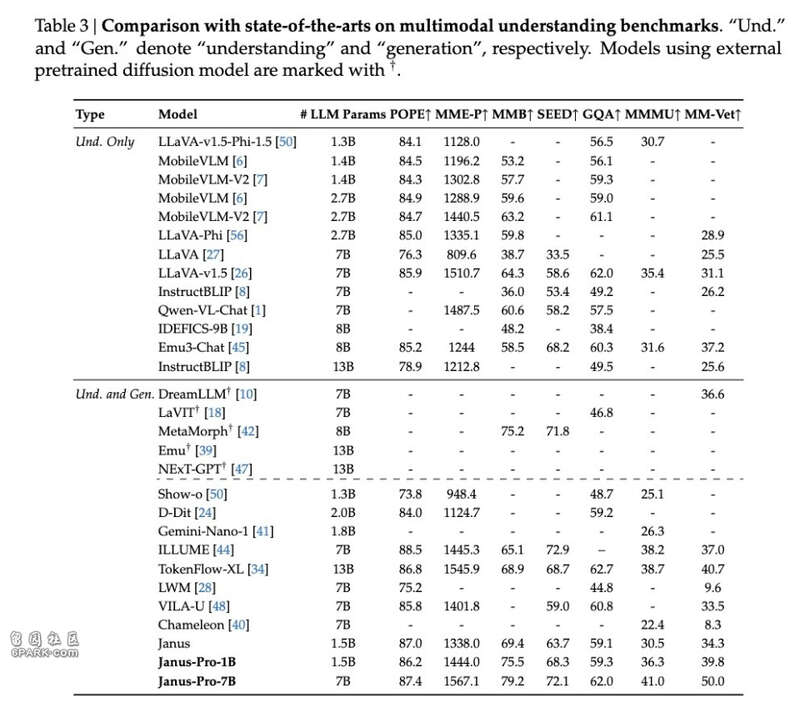
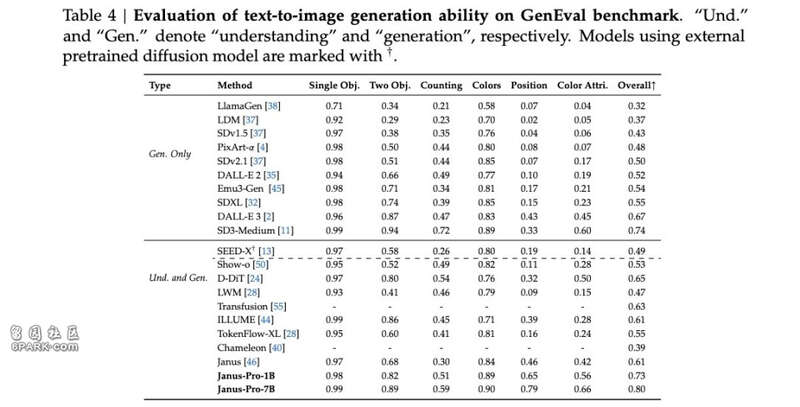
在图像生成评测上,Janus-Pro-7B在GenEval基准测试中达到0.80分,大幅领先于DALL-E 3(0.67分)和Stable Diffusion 3 Medium(0.74分)。
从实际使用上看,DeepSeek的Janus-Pro多模态理解和图像生成能力确实可圈可点。

在多模态理解方面,论文展示了三个范例,首先是地标识别能力。模型能准确识别杭州西湖的三潭印月景区,不仅能描述眼前的景象,还能理解其深层的文化内涵和历史意义。
其次是文本理解能力。面对一块写有"Serving Soul since Twenty Twelve"的黑板,模型不仅准确识别了主要文字,还注意到了周边的细节信息。
第三是上下文理解能力。在解读Tom and Jerry主题蛋糕时,模型展现出对动画角色设定、造型特点的深入理解,并能准确描述蛋糕上的设计元素。
而在图像生成方面,模型展示了八个不同场景的生成效果,涵盖了现实与想象两个维度。这些生成案例虽然输出分辨率仅为384×384,但每一幅画面都展现出细致的细节和准确的语义理解。
大一统模型的范式转变Deep Seek的Janus-Pro-7B通过这些测试数据首次证明了"理解"和"生成"这两个分离的任务可以在一个统一框架下达到各自的最优状态。
有趣的是,虽然传统统一模型声称受人脑启发,但却忽视了人脑最基本的解剖学特性 - 功能分区与整合的辩证关系。
在漫长的进化历程中,人脑形成了高度专业化的左右半球分工。左脑主导语言处理、逻辑分析和序列思维,右脑则专注于空间感知、艺术创造和整体认知。这种分工并非简单的功能隔离,而是通过胼胝体这一关键结构实现信息的深度整合,最终形成统一而完整的认知体验。
在此背景下,Janus Pro的架构设计仿佛就是在向人脑学习。其图像理解编码器专注于语义理解和特征提取,类似于左脑的分析功能;图像生成编码器负责创造性的图像生成,映射了右脑的艺术创造能力;而Transformer则扮演了类似胼胝体的角色,将两路信息进行深度统合。
更加相信胼胝体,相信Transformer的统合力,也许才是大一统模型进一步发展的关键思路。
Advertisements


